深度学习基础(基础知识0)(2)
可以看到,整个过程需要海量计算。所以,神经网络直到最近这几年才有实用价值,而且一般的 CPU 还不行,要使用专门为机器学习定制的 GPU 来计算。

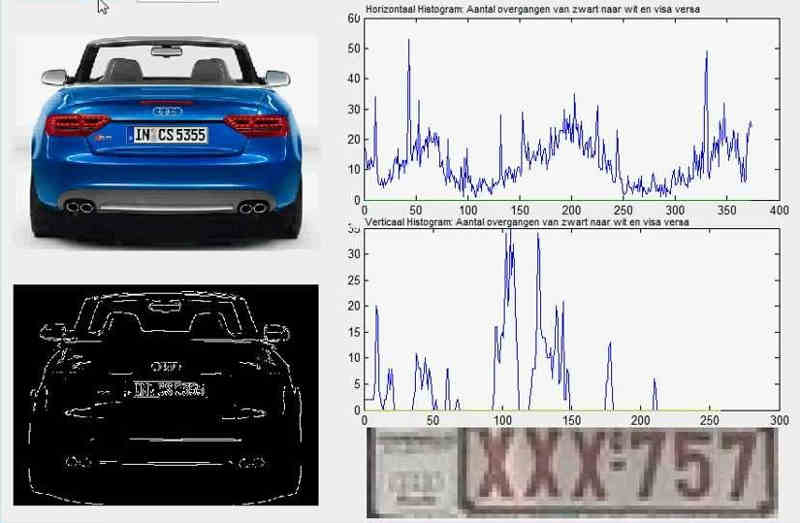
这个例子里面,车牌照片就是输入,车牌号码就是输出,照片的清晰度可以设置权重(w)。然后,找到一种或多种图像比对算法,作为感知器。算法的得到结果是一个概率,比如75%的概率可以确定是数字1。这就需要设置一个阈值(b)(比如85%的可信度),低于这个门槛结果就无效。
一组已经识别好的车牌照片,作为训练集数据,输入模型。不断调整各种参数,直至找到正确率最高的参数组合。以后拿到新照片,就可以直接给出结果了。
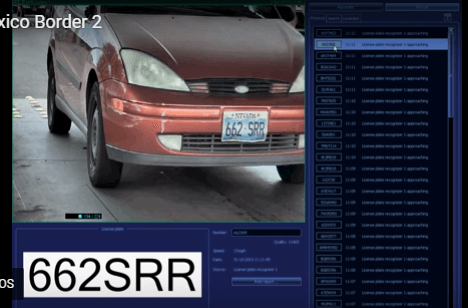
上面的模型有一个问题没有解决,按照假设,输出只有两种结果:0和1。但是,模型要求w或b的微小变化,会引发输出的变化。如果只输出0和1,未免也太不敏感了,无法保证训练的正确性,因此必须将输出改造成一个连续性函数。
即和w和b之间是线性关系,变化率是偏导数。这就有利于精确推算出w和b的值了。
这里可以看到Sigmoid 函数是使用深度学习范围最广的一类激活函数,具有指数函数形状 。正式定义为:
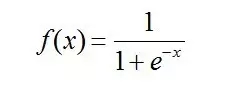
在深度学习中,信号从一个神经元传入到下一层神经元之前是通过线性叠加来计算的,而进入下一层神经元需要经过非线性的激活函数,继续往下传递,如此循环下去。由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的特征。
答:如果不使用激活函数,这种情况下每一层输出都是上一层输入的线性函数。无论神经网络有多少层,输出都是输入的线性函数,这样就和只有一个隐藏层的效果是一样的。这种情况相当于多层感知机(MLP)。
假设ANN网络已经搭建好了,在所有应用问题中(不管是网络结构,训练手段如何变化)我们的目标是不会变的,那就是网络的权值和偏置最终都变成一个最好的值,这个值可以让我们由输入可以得到理想的输出,于是问题就变成了y=f(x,w,b)(x是输入,w是权值,b为偏置)
最后的目标就变成了尝试不同的w,b值,使得最后的y=f(x)无限接近我们希望得到的值t,也就是让loss最小,loss可以用(y-t)^2的值尽可能的小。于是原先的问题化为了C(w,b)=(f(x,w,b)-t)^2取到一个尽可能小的值。这个问题不是一个困难的问题,不论函数如何复杂,如果C降低到了一个无法再降低的值,那么就取到了最小值(假设我们不考虑局部最小的情况)。
网络权值偏置更新问题 == f(x,w,b)的结果逼近t == C(w,b)=(f(x,w,b)-t)^2取极小值问题 == C(w,b)按梯度下降问题 ==取到极小值,网络达到最优。
主要是训练过程中,我们知道了输入和输出和groudtruth最后的真实结果,那么我们可以根据真实的结果-output得到误差值,再反向去推导前一层的误差,这样就可以更新我们的W 和B,比单纯的梯度下降去慢慢穷举一个个试试,速度快多了。
计算神经元h1的输入加权和,神经元h1的输出o1:(此处用到激活函数为sigmoid函数),同理,可计算出神经元h2的输出o2。
这样前向传播的过程就结束了,我们得到输出值为[0.75136079 , 0.772928465],与实际值[0.01 , 0.99]相差还很远,现在我们对误差进行反向传播,更新权值,重新计算输出。
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则),算出整体误差E(total)对w5的偏导值。
相关文章:
- [体育头条]有关异界修真之巅峰到底是什么
- [体育头条]小破孩表情包又是什么梗?
- [体育头条]关于台风凡亚比网友关心什么?
- [体育头条]有关魔兽世界前锋胸甲消息可靠
- [体育头条]有关重生之掌控世界怎么回事?
- [体育头条]关于御龙在天巴士具体是什么原
- [体育头条]有关老唐造车记怎么上了热搜?
- [体育头条]你就是我的生命又是个什么梗?
- [体育头条]鸟笼里的暹罗猫到底是什么情况
- [体育头条]主持人胡晨具体是什么原因?
- [体育头条]白皮松育苗到底是什么情况?
- [体育头条]有关天涯赤子心剧情介绍又是什
- [体育头条]具人同行湖南站到底是什么原因
- [体育头条]种瓜南山下网友如何看?
- [体育头条]有关这支烟灭了以后到底是什么
- [体育头条]偷星九月天舞台剧是怎么回事?
- [体育头条]汤臣倍健左旋肉碱怎么样究竟怎
- [体育头条]快打旋风3出招究竟怎么回事?
- [体育头条]于丹被轰下台究竟什么情况?
- [体育头条]铃木美恵子网友是怎么说的!
- 【雄关善治·五治融合】“五治融合”绘就和谐画卷——
- 改装档案BMW R nine T真是怎么改都好看!看看印度改出
- 1~8月南通全市工业投资稳健增长 亿元以上工业项目产出
- 有关五行带土的字的底层逻辑是什么?
- 值得但非首选]雷克萨斯NX200t两年详细使用感受
- b是什么车标
- 唇唇欲动无影有踪是真的吗?
- 湖北奥运冠军谌龙喜获赛季首冠 感叹坚持终于有了回报
- 斧头男大砍麦当劳事后操作更令人脊背发凉
- 淘宝分期付款(淘宝上如何分
- 华为美国子公司计划大规模裁员 中国雇员可回国并留在
- 第七届中国-亚欧博览会透露哪些积极信号?
- ROG6天玑版成安卓旗舰手机性能第一?真实用户评价亮了
- 关于魔少的逃跑俏新娘又是什么梗?
- 易方达天天理财货币A
- 面瘫将军求子记具体内容是什么?
- 美格智能技术股份有限公司第二届监事会第十次会议决议
- 加盟商百万欠款难追回 鱼乐贝贝“加盟圈套”何时终结
- 4080显卡需要多少w电源笔记本什么时候出?
- 青海小西牛生物乳业股份有限公司
- 多多自走棋进入NEST电竞项目 已经跟V社彻底分家了
- 微信悄悄测试新功能:发语音可转文字网友直呼太方便!
- 女儿第一次来“大姨妈”妈妈一定要跟她说三句话关系她
- 小学数学趣味100题暑假在家也能边玩边学习(含答案)
- 搞笑段子:第一次去男朋友家没想到来了一大家子亲戚…
- 【安雷ABO】(R)抗拒从严【一发完】
- 更快更好更便捷
- 威海市统一路小学看看网友是如何评论的!
- 北理工:2019增设三大专业 继续推行0调剂 0退档
- 华怡:MVR蒸发器、三效多效蒸发器、升降膜蒸发器厂家
- 有关王若伊释小龙这是不是真相?
- 中建八局二公司与德州市建筑行业企业举行战略合作协议
- 第二届世界互联网大会
- 搞笑GIF图:看了一会儿才明白是啥
- 南京本地宝-爱上本地宝生活会更好
- 战舰少女r公式大全
- 中华人民共和国国防部
- 郭晨冬谈被解约的黑龙何以UFC一战成名但说黑人长相蠢
- 95开头的8位数骚扰电话越来越多 到底什么来头?
- 关于我要上春晚20110717背后的逻辑是什么?