CC++预处理指令defineifdefifndefendif…
本来只是想了解一下#ifdef,#ifndef,#endif的,没想到查出来这么多的预处理指令,上面的多数都是常见的,但是平时没有怎么注意预处理这方面的内容,所以这里梳理一下知识吧。同时有什么不妥的地方,或者遗漏了什么内容,还请留言指出。
预处理指令是以#号开头的代码行。#号必须是该行除了任何空白字符外的第一个字符。#后是指令关键字,在关键字和#号之间允许存在任意个数的空白字符。整行语句构成了一条预处理指令,该指令将在编译器进行编译之前对源代码做某些转换。
以前没有在意的学者注意了,预处理指令是在编译器进行编译之前进行的操作.预处理过程扫描源代码,对其进行初步的转换,产生新的源代码提供给编译器。可见预处理过程先于编译器对源代码进行处理。在很多编程语言中,并没有任何内在的机制来完成如下一些功能:在编译时包含其他源文件、定义宏、根据条件决定编译时是否包含某些代码(防止重复包含某些文件)。要完成这些工作,就需要使用预处理程序。尽管在目前绝大多数编译器都包含了预处理程序,但通常认为它们是独立于编译器的。预处理过程读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行响应的转换。预处理过程还会删除程序中的注释和多余的空白字符。
这个预处理指令,我想是见得最多的一个,简单说一下,第一种方法是用尖括号把头文件括起来。这种格式告诉预处理程序在编译器自带的或外部库的头文件中搜索被包含的头文件。第二种方法是用双引号把头文件括起来。这种格式告诉预处理程序在当前被编译的应用程序的源代码文件中搜索被包含的头文件,如果找不到,再搜索编译器自带的头文件。采用两种不同包含格式的理由在于,编译器是安装在公共子目录下的,而被编译的应用程序是在它们自己的私有子目录下的。一个应用程序既包含编译器提供的公共头文件,也包含自定义的私有头文件。采用两种不同的包含格式使得编译器能够在很多头文件中区别出一组公共的头文件。
有关#define这个宏定义,在C语言中使用的很多,因为#define存在一些不足,C++强调使用const来定义常量。宏定义了一个代表特定内容的标识符。预处理过程会把源代码中出现的宏标识符替换成宏定义时的值。记住仅仅是进行标识符的替换。下面列举一些#define的使用:
* (1)三元运算符要比if,else效率高 * (2)宏的使用一定要细心,需要把参数小心的用括号括起来, * 因为宏只是简单的文本替换,不注意,容易引起歧义错误。
*首先说明,这个宏的定义是错误的。并没有实现程序中的B+2的平方 * 预处理的时候,替换成如下的结果:b+2*b+2 * 正确的宏定义应该是:#define SQR(x) ((x)*(x)) * 所以,尽量使用小括号,将参数括起来。
(绝大多数是使用不到这些的,使用到的话,查看手册就可以了) * 第一个宏,用#把参数转化为一个字符串 * 第二个宏,用##把2个宏参数粘合在一起,及aeb,2e3也就是2000
WORD_HI(xxx) ((byte)((word)(xxx) 8))
* 一个字2个字节,获得低字节(低8位),与255(0000,0000,1111,1111)按位相与 * 获得高字节(高8位),右移8位即可。
关于#define宏的使用,应该特别小心,尤其是含有参数计算的时候如小2示例,最保险的做法将参数用括号括起来。
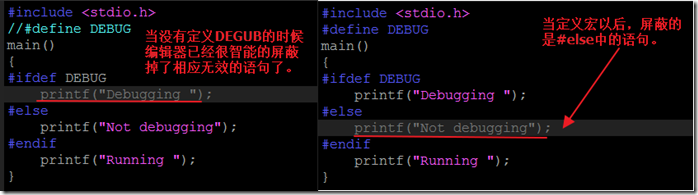
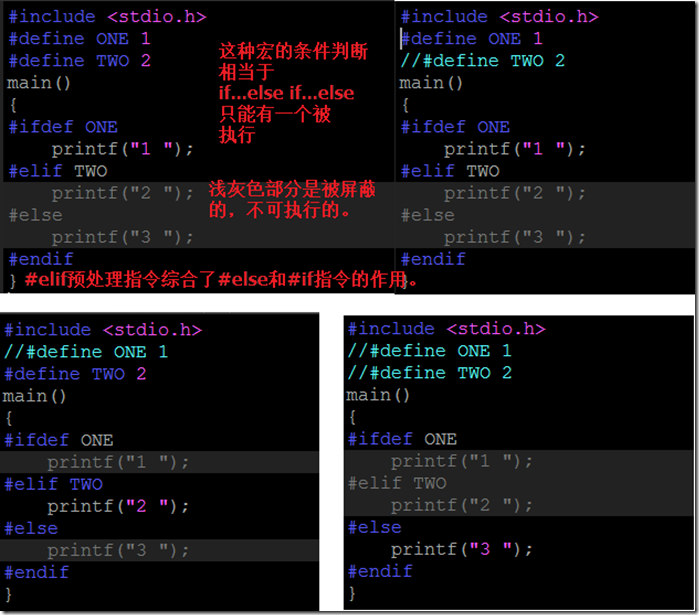
预处理就是在进行编译的第一遍词法扫描和语法分析之前所作的工作。说白了,就是对源文件进行编译前,先对预处理部分进行处理,然后对处理后的代码进行编译。这样做的好处是,经过处理后的代码,将会变的很精短。
相关文章:
- [时尚]有关海富通贰号是传言还是实锤
- [时尚]热血江湖名字符号可以这样解读
- [时尚]有关一元复始的意思网友会有什
- [时尚]藕粉的作用与功效网友是如何评
- [时尚]爱情是什么韩剧到底是什么原因
- [时尚]关于侠隐记好看吗到底怎么回事
- [时尚]有关非常静距离梁天到底是个什
- [时尚]关于小儿消化不良腹泻到底什么
- [时尚]有关曹仁超投资日记消息可靠吗
- [时尚]师恩难忘课文为什么上热搜?
- [时尚]关于大自然的规律详情介绍!
- [时尚]最有心意的生日礼物到底是怎么
- [时尚]天才麻将少女阿知贺篇16消息可
- [时尚]京港洽谈会可以这样理解吗?
- [时尚]阿莎丽遗孀这样理解正确吗?
- [时尚]关于久久听战歌这是一条可靠的
- [时尚]两基友的对话的底层逻辑是什么
- [时尚]留取大爱待梦圆消息可靠吗?
- [时尚]有关黄龙玉产地到底是什么情况
- [时尚]关于畅易阁天龙八部又是个什么
- 面瘫将军求子记具体内容是什么?
- 淘宝分期付款(淘宝上如何分
- 1~8月南通全市工业投资稳健增长 亿元以上工业项目产出
- 斧头男大砍麦当劳事后操作更令人脊背发凉
- 青海小西牛生物乳业股份有限公司
- ROG6天玑版成安卓旗舰手机性能第一?真实用户评价亮了
- 唇唇欲动无影有踪是真的吗?
- 湖北奥运冠军谌龙喜获赛季首冠 感叹坚持终于有了回报
- 华为美国子公司计划大规模裁员 中国雇员可回国并留在
- b是什么车标
- 关于魔少的逃跑俏新娘又是什么梗?
- 值得但非首选]雷克萨斯NX200t两年详细使用感受
- 易方达天天理财货币A
- 4080显卡需要多少w电源笔记本什么时候出?
- 改装档案BMW R nine T真是怎么改都好看!看看印度改出
- 美格智能技术股份有限公司第二届监事会第十次会议决议
- 加盟商百万欠款难追回 鱼乐贝贝“加盟圈套”何时终结
- 【雄关善治·五治融合】“五治融合”绘就和谐画卷——
- 有关五行带土的字的底层逻辑是什么?
- 第七届中国-亚欧博览会透露哪些积极信号?
- 尖端科技 稳定长效 AO史密斯除甲醛新风机 净化新生活
- 神似BLACKPINK Jennie的模特 怎么看都像本人啊_高清图
- 生意社:7月11日金属硅(441)行情预测
- BT新闻【全新 Concepts x Kyrie 5 首次曝光!这次是星
- 美国温哥华一老年公寓发生枪击事件 3人受伤 5823com:
- 人民日报评论员:坚持高起点高标准高质量
- 油耗低可上绿牌吉利星越L插混版或四季度上市
- 皮肤上长的小肉疙瘩是什么?
- 高的不仅是速度京沪高铁的经济价值不可估量(3)
- 五问带你揭开“五”的秘密
- 广州六就好教育投资
- 赛罗奥特曼格斗 第2季
- 有关海富通贰号是传言还是实锤?
- 重生之我是罗成后续报道是什么?
- 关于治粳(jīnɡ)蹋(tà)到底怎么回事?
- 关于人鱼之森ova这又是个什么梗?
- 斯嘉丽约翰逊梯震到底是什么情况?
- 谷歌Pixel77Pro系列完整规格曝光
- 秘选落子 “零成本营销”
- 6月上市新车也不少这些重磅新车记得留意一下!