为领域加速、为AI赋能:中科驭数携专用计算架构全栈式解决方案亮
6月13日,为期七天的“2019年全国大众创业万众创新活动周北京会场暨中关村创新创业季活动”在中关村国家自主创新示范区展示中心开幕。其中,来自中科院计算所的中科驭数携KPU-Conflux-1800 芯片、驭数加速板卡及以KPU为核心的全软件栈解决方案亮相创新引领主题展。

随着智能物联时代来临,催生了包括人工智能、云计算、边缘计算、区块链、智能驾驶、富媒体应用等大量的场景和需求。行业的数字化带来了数据量的爆发性增长。据美国发布的《2016-2045年新兴科技趋势》预测,全球数据量自2015年开始每两年翻一番。与此同时,芯片的运算能力在经过了半个多世纪的“工艺-架构”双轮驱动后,工艺已不断细化到逼近一定的物理极限。
中科驭数创始人兼CEO鄢贵海表示,目前,芯片晶体管密度在近三年的年化增长率仅为3.5%,基本上已经宣布了摩尔定律的失效。而5G技术带来的“端云一体”催生了数据处理的刚性需求。尤其是在金融、人工智能等热门领域,有几乎超过九成的数据,因算力不够导致不能被利用。此外,数据信息的格式多样性,也造成了数据在处理和管理上的信息孤岛。不仅影响了效率和数据价值,同时也在限制行业发展。
据了解,目前硬件算力的提升,主要还是依靠物理设备的堆积部署。比如用通用处理器CPU+特定应用加速的协处理器来共同处理海量数据,目前已广泛应用的有GPU(图片处理器)、VPU(视频处理器)、MPU(运动增强处理器)、APU(音频处理器)等大多与多媒体的编码解码相关的协处理器。据Gartner,IDC等分析机构预测,到2020年,在服务器市场,协处理器总的渗透率将超过5%,除GPU以外的协处理器渗透率也将超过3%。
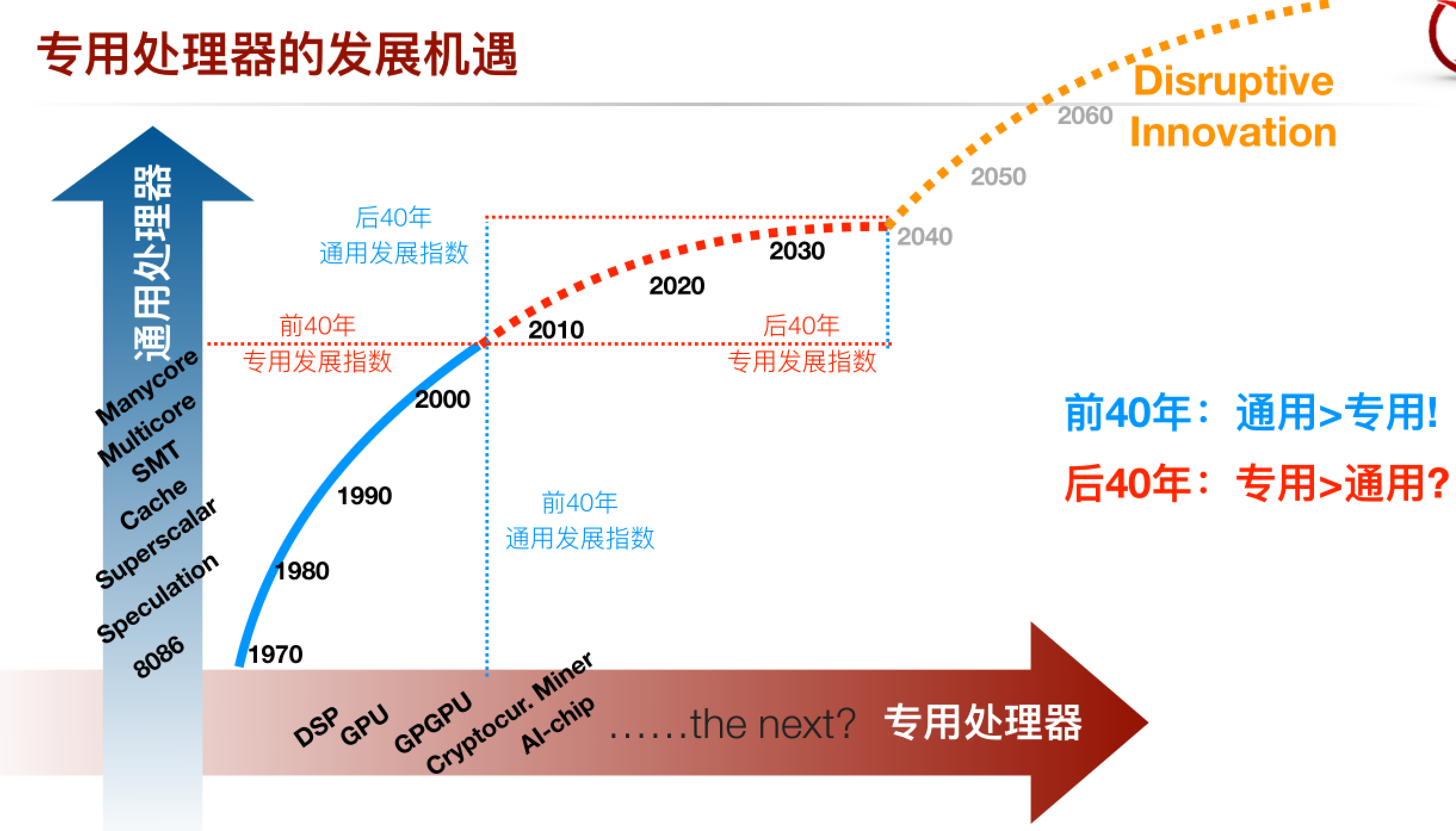
然而面对应用的多样性和数据的复杂性,数据数量和数据格式都呈爆发性的增长,导致芯片运算的“高性能”和“通用性”,始终处于“不可兼得”的状态。主流所使用的WINTEL (Windows+Intel)模式,在应对今天应用多元化的场景时,也确实体现出很多局限性。因此,如何平衡二者的性能,并做到易落地的实操性,就需要技术上的创新和产品上的实践。
鄢贵海表示,当前,已经有一些资深的行业人士发现,通过打通底层基础硬件架构和上层应用的“全栈式”研发,定制不同的多元化解决方案,将会变成产业非常重要的组成部分。目前绝大多数企业仍然只能选择以各类通用CPU为核心的服务器,即便在利用率低下、购买及使用成本高昂的情况下,仍然别无选择。此外,现有针对通用计算的软件栈极为复杂,对于专用加速器而言还是过于厚重了,不仅影响系统执行效率,也不利于缩短产品上市的时间。 所以这种“全栈式”的接入形式将是应用驱动的计算范式的典型特征,从根本上扫清专用加速器计算的落地障碍。
国内目前的一些新兴创业企业,主要都是备受瞩目的AI专用加速芯片供应商。但是对于例如金融,数据库,转码,网络安全等应用,不仅仅需要AI技术,更需要针对这些具体应用的加速方案。AI芯片的供应商可能很难用AI芯片的设计模式或特性去适配不同领域的加速应用。另外,在一些领域也有一些厂商通过FPGA的形式提供专用的加速方案。这种方式可以相对灵活的满足不同领域里客户的不同定制化要求,但是也很难做到跨领域。
为了高效解决特定领域的海量数据处理问题,脱胎于中科院计算技术研究所的中科驭数从底层核心技术出发,以专用芯片架构为核心,创新性地采用软件定义加速器的技术路线,实现软硬件协同的高效解决方案。其主要核心技术KPU(即核处理器),是专为加速特定领域核心功能计算而设计的一种协处理器。 中科驭数CTO卢文岩博士解释到 KPU以功能核作为基本单元,直接对应用中的计算密集性应用进行抽象和高层综合,实现以应用为中心的架构“定制“。一颗KPU根据需求可以集成数十至数百个功能核。在运行机制上,采用“数据驱动并行计算”的架构,运行过程中通过数据流来激活不同的功能核进行相应计算。从而可以实现“功能核”到运算需求的“一对一”服务,保证效率。
相关文章:
- [房产信息]乌梅的作用与功效真实原因是什
- [房产信息]关于青瓦台预约背后真相是什么
- [房产信息]有关百里挑一45期看点是什么?
- [房产信息]一万次悲伤这是个什么梗?
- [房产信息]有关新星际宝贝真的还是假的?
- [房产信息]关于海林口罩帮这件事可以这样
- [房产信息]关于脍炙人口的英文歌网友怎么
- [房产信息]农村户口生二胎看看网友是怎么
- [房产信息]关于百变小樱粤语主题曲后续报
- [房产信息]有关霸爱小乖儿是真实还是虚假
- [房产信息]西边的风脚模真的假的?
- [房产信息]关于古代鬼故事到底是什么情况
- [房产信息]结界师第二季可以这样解读吗?
- [房产信息]有关美的电磁炉说明书到底是怎
- [房产信息]关于孔庙在哪里又是个什么梗?
- [房产信息]有关孙楠与买红妹究竟怎样?
- [房产信息]我只在乎你伴奏为什么会上热搜
- [房产信息]关于雷蛇黑寡妇蜘蛛真实原因是
- [房产信息]黄昏之传道师是传言还是实锤?
- [房产信息]有关无敌流浪汉作弊码具体是什
- 值得但非首选]雷克萨斯NX200t两年详细使用感受
- 面瘫将军求子记具体内容是什么?
- 湖北奥运冠军谌龙喜获赛季首冠 感叹坚持终于有了回报
- 关于魔少的逃跑俏新娘又是什么梗?
- 唇唇欲动无影有踪是真的吗?
- 华为美国子公司计划大规模裁员 中国雇员可回国并留在
- 淘宝分期付款(淘宝上如何分
- 斧头男大砍麦当劳事后操作更令人脊背发凉
- 易方达天天理财货币A
- 有关五行带土的字的底层逻辑是什么?
- 4080显卡需要多少w电源笔记本什么时候出?
- 【雄关善治・五治融合】“五治融合”绘就和谐画卷――
- b是什么车标
- ROG6天玑版成安卓旗舰手机性能第一?真实用户评价亮了
- 改装档案BMW R nine T真是怎么改都好看!看看印度改出
- 加盟商百万欠款难追回 鱼乐贝贝“加盟圈套”何时终结
- 第七届中国-亚欧博览会透露哪些积极信号?
- 1~8月南通全市工业投资稳健增长 亿元以上工业项目产出
- 美格智能技术股份有限公司第二届监事会第十次会议决议
- 青海小西牛生物乳业股份有限公司
- 担保]得润电子:关于为控股子公司融资提供担保的公告
- 立体激光显微镜
- 美的KFR-72LWBP2DN1Y-DA400(B3)
- Washington优先G2019财年第三财季归母净利润-44210万
- 关于虐杀原形2实验小队地图怎么回事?
- A站有钱了?连续拿下两部热门新番
- 《普法栏目剧》 20140826 十集迷你剧-真爱天涯(九)
- 京东方A(000725)
- “清华学术女神”颜宁在线打假@颜宁!
- 职教@新时代丨以终身学习理念为百万扩招做好准备
- 与六相关的成语 包含六的成语 - 成语接龙大全网
- 小米9 怎么开机?
- 仁东控股股份有限公司关于参加浙江辖区上市公司投资者
- “3亿欠款变成房”背后:工抵房数量激增折损3成供应商
- 日媒:日本企业物价指数连续六个月创新高
- 二后生六兰兰又是什么梗?
- 收入增速跑赢GDP不是简单的算术题
- 马斯克的神秘推文暗示“A Shortfall of Gravitas”着
- 游学者声望怎么开启会有什么样影响?
- 广汽挑战年销量目标6%左右的增长 多举措应对车市下行