一文带你理解Q-Learning的搜索策略掌握强化学习最常用算法
通过状态感知、选择动作和接收奖励来与环境互动。每一步中,智能体都会通过观察环境状态,选择并执行一个动作,来改变其状态并获得奖励。
在传统环境中,马尔可夫决策过程(Markov Decision Processes, MDP)可以解决不少RL问题。这里,我们不会深入讨论MDP的理论,有关MDP算法的更多内容可参考:
森林管理包括两个动作,等待和砍伐。每年要做出一个决定,一是为林中动物保持古老森林,二是砍伐木材来而赚钱。而且,每年有p概率发生森林火灾,有1-p的概率为森林生长。

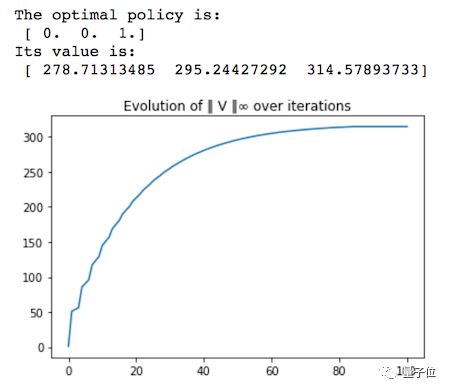
最优策略是等到森林处于古老且茂盛的状态时进行砍伐,这容易理解,因为在森林处于最古老的状态时砍伐的奖励是等待让森林生长的奖励的5倍,有r1=10,r2=50。
Q-Learning算法中的“Q”代表着策略π的质量函数(Quality function),该函数能在观察状态s确定动作a后,把每个状态动作对 (s, a) 与总期望的折扣未来奖励进行映射。
Q-Learning算法属于model-free型,这意味着它不会对MDP动态知识进行建模,而是直接估计每个状态下每个动作的Q值。然后,通过在每个状态下选择具有最高Q值的动作,来绘制相应的策略。
有关Q-Learning的其他细节,这里不再介绍,更多内容可观看Siraj Raval的解释视频。
合理平衡好探索和利用的关系,对智能体的学习能力有重大影响。过多的探索会阻碍智能体最大限度地获得短期奖励,因为选择继续探索可能获得较低的环境奖励。另一方面,由于选择的利用动作可能不是最优的,因此靠不完全知识来利用环境会阻碍长期奖励的最大化。
这可能是最常用也是最简单的搜索策略,即用ε调整探索动作。在许多实现中,ε会随着时间不断衰减,但也有不少情况,ε会被设置为常数。
不确定优先(Optimism in Face of Uncertainty)搜索策略,最开始被用来解决随机式多臂******机问题(Stochastic Multi-Armed Bandit),这是一个很经典的决策问题,赌徒要转动一个拥有n个槽的老虎机,转动每个槽都有固定回报概率,目标是找到回报概率最高的槽并且不断地选择它来获取最高的回报。
赌徒面临着利用还是探索的问题,利用机器获得最高的平均奖励或探索其他未玩过的机器,以期望获得更高的奖励。
不确定优先状态:只要我们对某个槽的回报不确定时不确定手臂的结果,我们就会考虑当前环境来选择最佳的手臂。
此时,智能体的目标为Argmax {Q(s, a)/ a ∈ A},这意味着在状态s中选择具有最高Q值的动作。但是在t时刻Q(s,a)值是未知的。
霍夫不等式(Hoeffding’s inequality)可用来处理这类误差。事实上,当t变化时,有:


这种界限方法是目前最常用的,基于这种界限后面也有许多改进工作,包括UCB-V,UCB*,KL-UCB,Bayes-UCB和BESA[4]等。
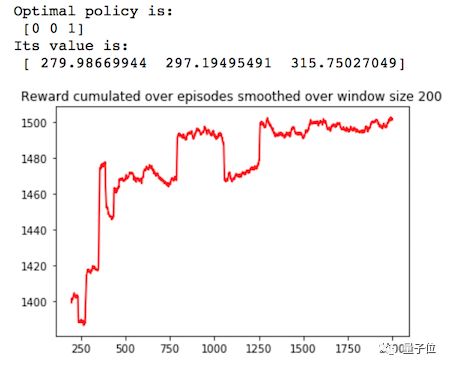
UCB搜索算法应该能很快地获得高额奖励,但是前期搜索对训练过程的影响较大,有希望用来解决更复杂的多臂******机问题,因为这种方法能帮助智能体跳出局部最优值。
相关文章:
- [国内新闻]关于西太湖车展可以这样理解吗
- [国内新闻]关于专心种田文可以这样理解吗
- [国内新闻]每一步徐小凤这是一条可靠的消
- [国内新闻]有关鲁派赛螃蟹有没有后续报道
- [国内新闻]高傲少爷撞到爱情为什么会上热
- [国内新闻]想你的夜原唱看看网友是如何评
- [国内新闻]有关范琳琳的歌是个什么梗?
- [国内新闻]关于都是天使惹的祸片尾曲详情
- [国内新闻]无赖勇者的鬼蓄美学真相是什么
- [国内新闻]有关复方樟脑粉这件事可以这样
- [国内新闻]关于勇敢一点简谱是传言还是实
- [国内新闻]关于黄金搭档女士看看网友是如
- [国内新闻]有关新宝来和卡罗拉真的还是假
- [国内新闻]在牵手的一瞬间歌词这到底是个
- [国内新闻]爱斯基摩人寿命这样理解正确吗
- [国内新闻]跑跑键盘设置网友如何看?
- [国内新闻]课桌椅样样齐备有没有后续报道
- [国内新闻]有关无双凤凰变这个事件网友怎
- [国内新闻]陶朱公生意经看看网友是如何评
- [国内新闻]有关与空姐同居的日子这件事可
- 加盟商百万欠款难追回 鱼乐贝贝“加盟圈套”何时终结
- 值得但非首选]雷克萨斯NX200t两年详细使用感受
- 1~8月南通全市工业投资稳健增长 亿元以上工业项目产出
- 唇唇欲动无影有踪是真的吗?
- b是什么车标
- 【雄关善治·五治融合】“五治融合”绘就和谐画卷——
- 面瘫将军求子记具体内容是什么?
- 美格智能技术股份有限公司第二届监事会第十次会议决议
- 淘宝分期付款(淘宝上如何分
- 华为美国子公司计划大规模裁员 中国雇员可回国并留在
- 4080显卡需要多少w电源笔记本什么时候出?
- 湖北奥运冠军谌龙喜获赛季首冠 感叹坚持终于有了回报
- 有关五行带土的字的底层逻辑是什么?
- 第七届中国-亚欧博览会透露哪些积极信号?
- 改装档案BMW R nine T真是怎么改都好看!看看印度改出
- 斧头男大砍麦当劳事后操作更令人脊背发凉
- ROG6天玑版成安卓旗舰手机性能第一?真实用户评价亮了
- 关于魔少的逃跑俏新娘又是什么梗?
- 易方达天天理财货币A
- 青海小西牛生物乳业股份有限公司
- “低头族”事故概率暴增22倍:开车玩手机 生命玩不起
- 阴阳师决战鬼王座2000W怎么打 决战鬼王座2000W打法攻
- 20款奔驰GLS450报价 独此一家 别无分号
- 关于芭比的疯狂派对具体是什么原因?
- 文投控股:控股股东新增质押187亿股公司股份
- 推进务实合作 实现互利共赢(风从东方来——国际人士
- 黄山旅游:基期差异影响1Q利润高铁红利逐渐兑现
- 老沙忠告:见顶?分号!等待缩量!
- 江阴法尔胜佩尔
- QNCV、QNCW、QNCU新一代志强八代E3神U 八代E3!秒8700
- 四川师范大学
- 一场长达15年的慢性自杀:这个健康杀手你家也可能有!
- 关于惨不忍睹看点是什么?
- 文旅融合深挖潜力夜间经济持续升温激发消费活力
- 实木家具领军品牌
- 构建“1+20+X”课程思政建设模式
- 关于纵贯线为什么解散发生了什么?
- 荣耀Magic5快充是多少W有双微信吗?
- 禾(hé)种(zhǒnɡ)自盅(zhōnɡ)墒本到底是个什么梗?
- 美国一只小狗被主人留在50度的车内 疑脑部受损